
📝 Publications
# denotes co-first authors
🎙 Singing Voice Synthesis
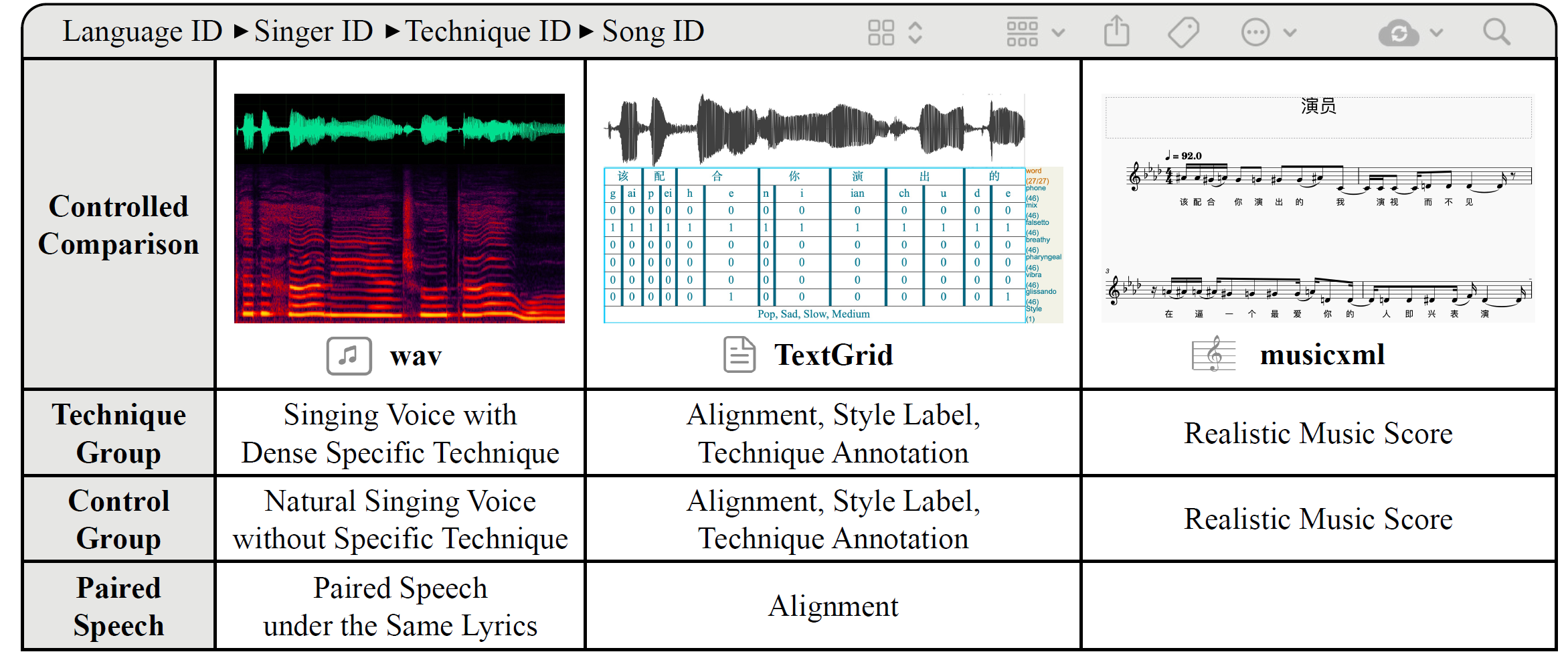
GTSinger: A Global Multi-Technique Singing Corpus with Realistic Music Scores for All Singing Tasks
Yu Zhang, Changhao Pan#, Wenxiang Guo#, et al.

- GTSinger is a large Global, multi-Technique, free-to-use, high-quality singing corpus with realistic music scores, designed for all singing tasks.
- Our work is promoted by multiple media and forums, such as
,
, and
.
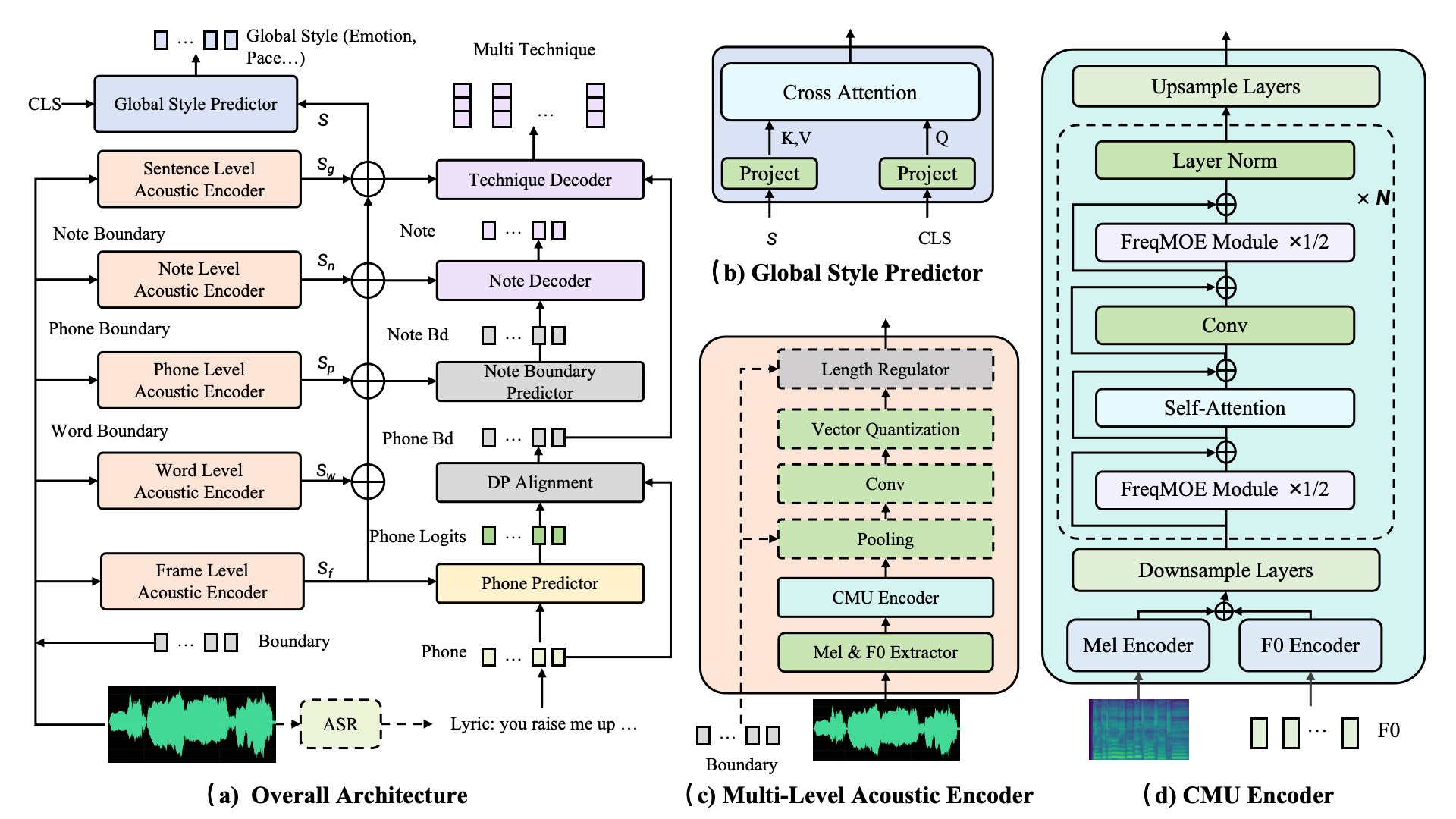
STARS: A Unified Framework for Singing Transcription, Alignment, and Refined Style Annotation
Wenxiang Guo#, Yu Zhang#, Changhao Pan#, et al.
Project |

- STARS is a unified framework for singing transcription, alignment, and refined style annotation based on hierarchical representation learning.
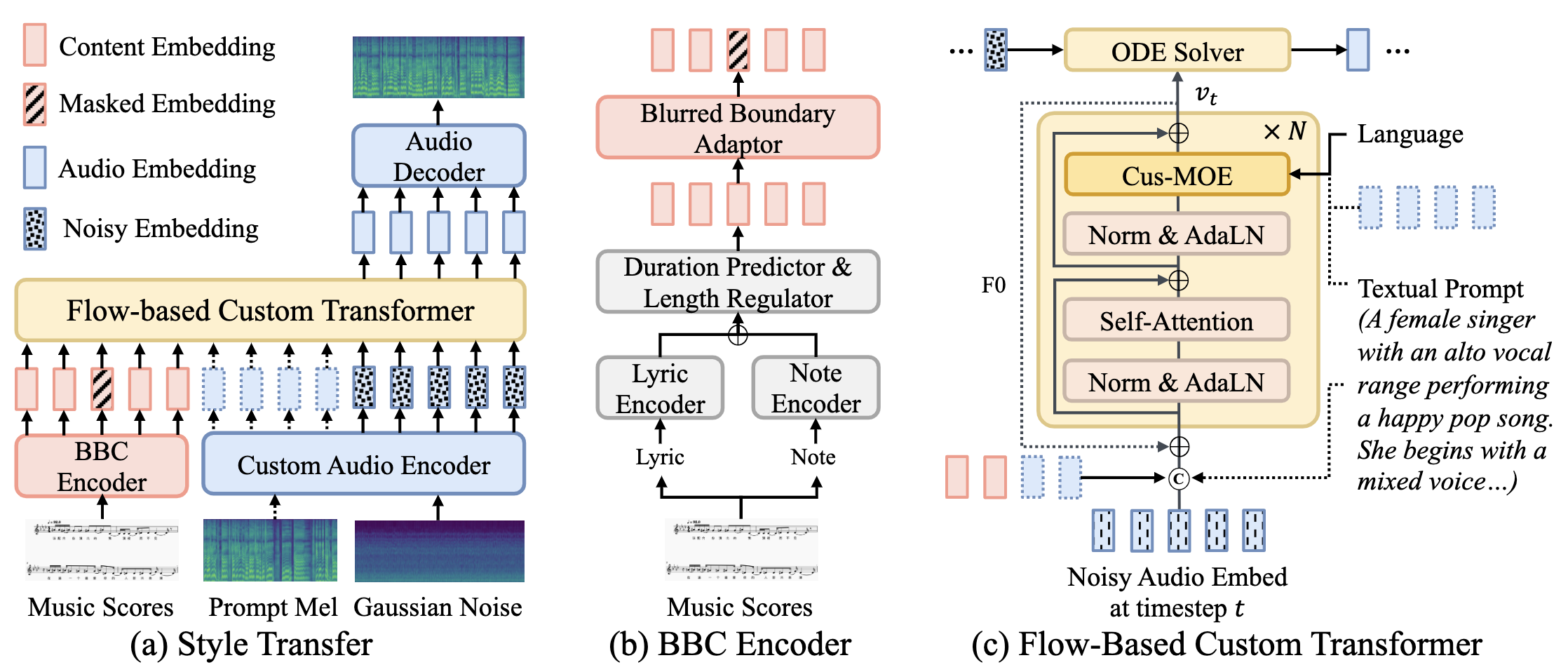
TCSinger 2: Customizable Multilingual Zero-shot Singing Voice Synthesis
Yu Zhang#, Wenxiang Guo#, Changhao Pan#, et al.
Project |

- TCSinger 2 is a multi-task multilingual zero-shot SVS model with style transfer and style control based on various prompts.
-
EMNLP-2024TCSinger: Zero-Shot Singing Voice Synthesis with Style Transfer and Multi-Level Style Control, Yu Zhang, Ziyue Jiang, Ruiqi Li, Changhao Pan, Jinzheng He, Rongjie Huang, Chuxin Wang, Zhou Zhao. | Project | -
AAAI-2025TechSinger: Technique Controllable Multilingual Singing Voice Synthesis via Flow Matching, Wenxiang Guo, Yu Zhang, Changhao Pan, et. al. | Project |


👂 Spatial Audio
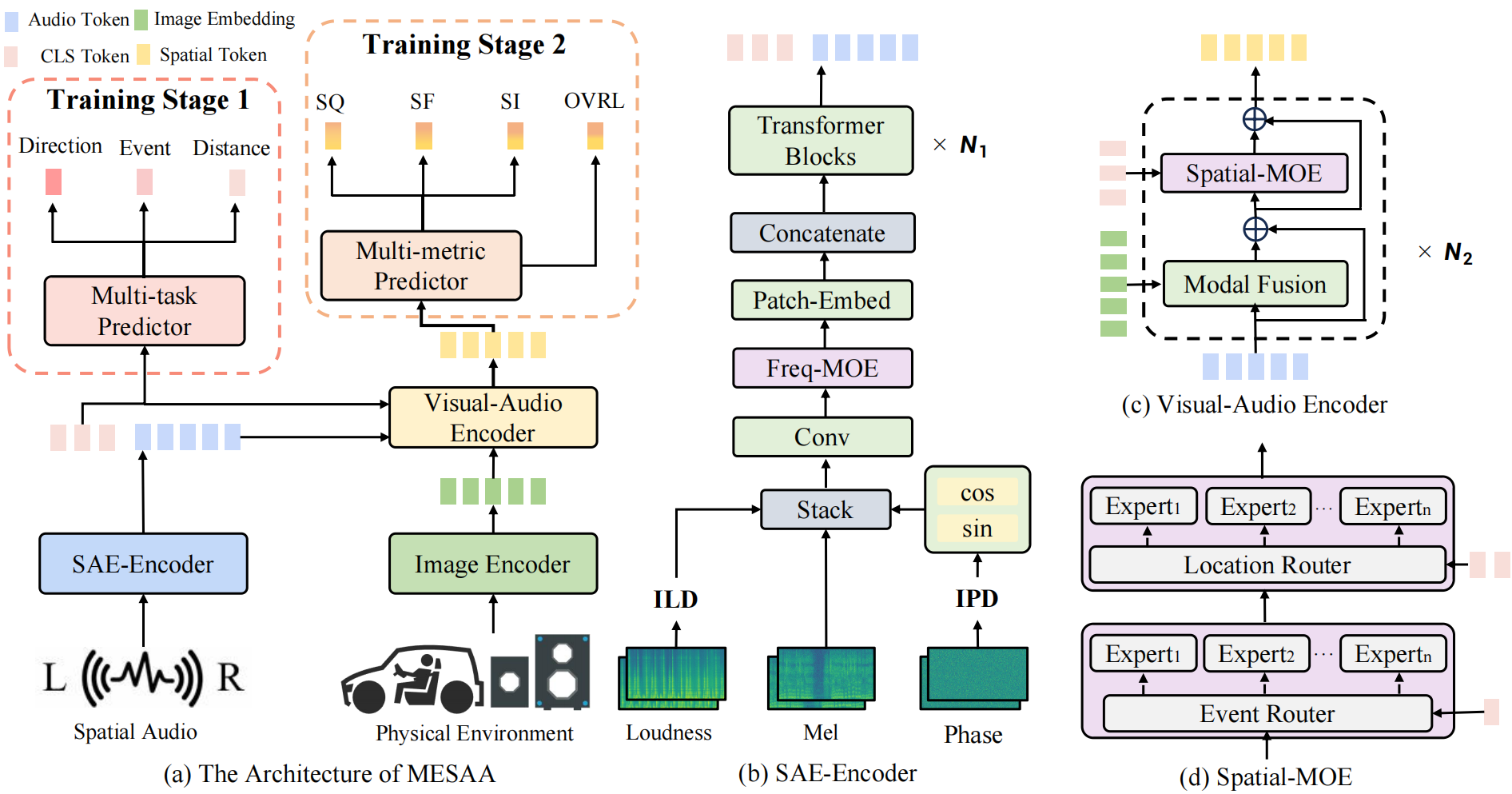
A Multimodal Evaluation Framework for Spatial Audio Playback Systems: From Localization to Listener Preference
Changhao Pan#, Wenxiang Guo, Yu Zhang, et al.
- PSA-MOS provides 50 hours of high-quality spatial audio recordings, with detailed localization annotations and fine-grained MOS ratings.
- MESA is a multimodal evaluation framework for spatial audio playback systems which exhibits strong correlation with human perceptual assessments.
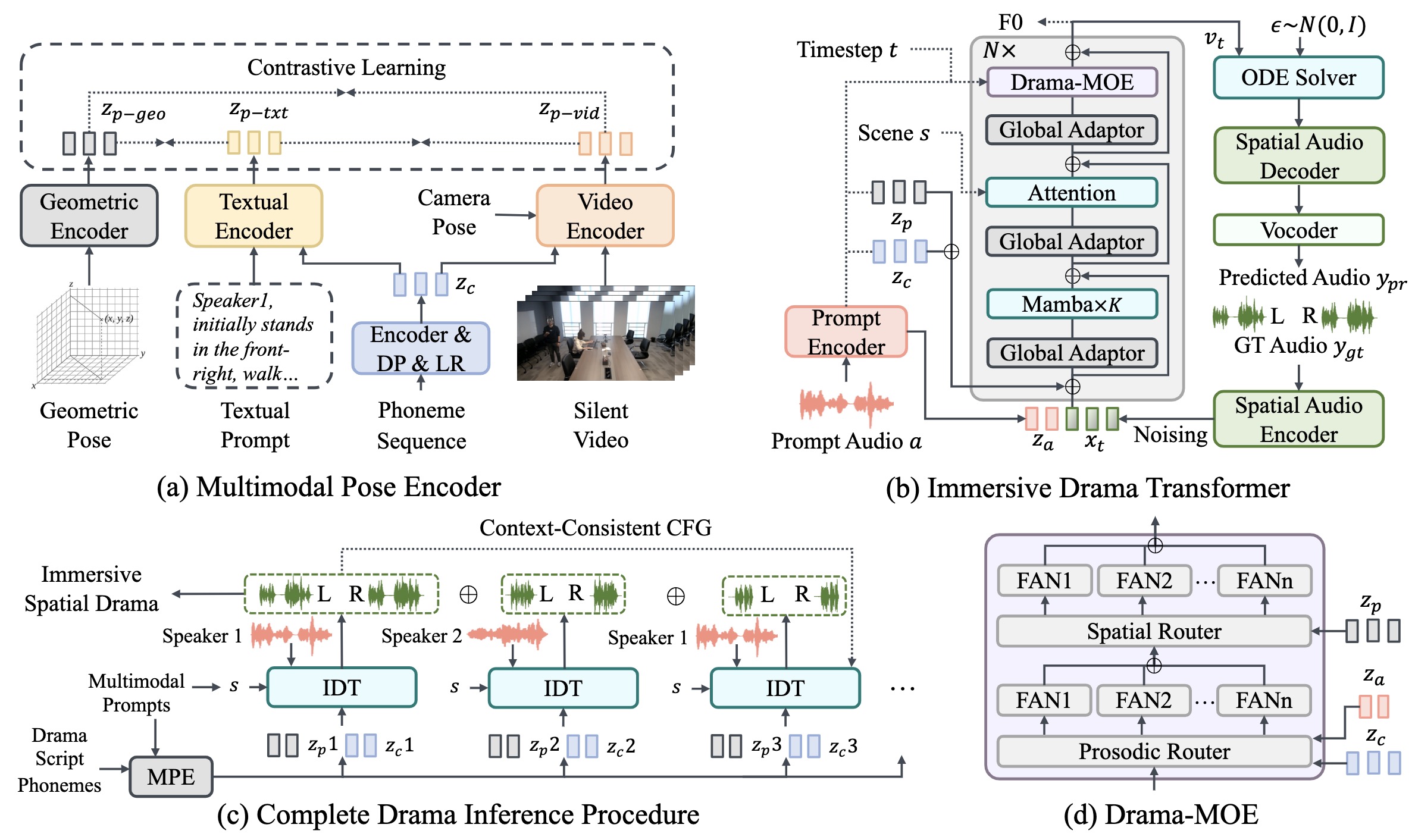
ISDrama: Immersive Spatial Drama Generation through Multimodal Prompting
Yu Zhang#, Wenxiang Guo#, Changhao Pan#, et al.

- MRSDrama is the first multimodal recorded spatial drama dataset, containing binaural drama audios, scripts, videos, geometric poses, and textual prompts.
- ISDrama is the first immersive spatial drama generation model through multimodal prompting.
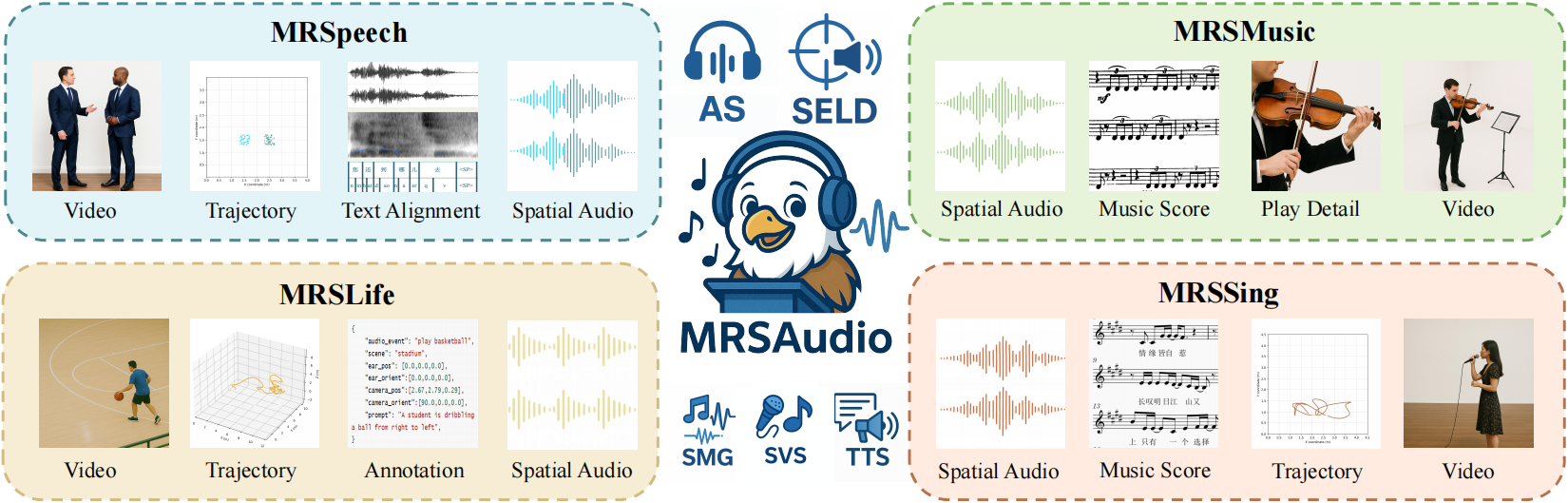
MRSAudio: A Large-Scale Multimodal Recorded Spatial Audio Dataset with Refined Annotations
Wenxiang Guo#, Changhao Pan#, Zhiyuan Zhu#, Xintong Hu#, et al.
- The largest recorded spatial audio dataset contains four scenarios: daily life, singing, music, and speech, with a total duration of 500 hours.
- Supports multiple spatial audio tasks: audio spatialization, spatial TTA, acoustic event localization and detection(SELD), etc.
AACL-IJCNLPASAudio: A Survey of Advanced Spatial Audio Research, Zhiyuan Zhu, Yu Zhang, Wenxiang Guo, Changhao Pan, et al. |

🎼 Music Generation
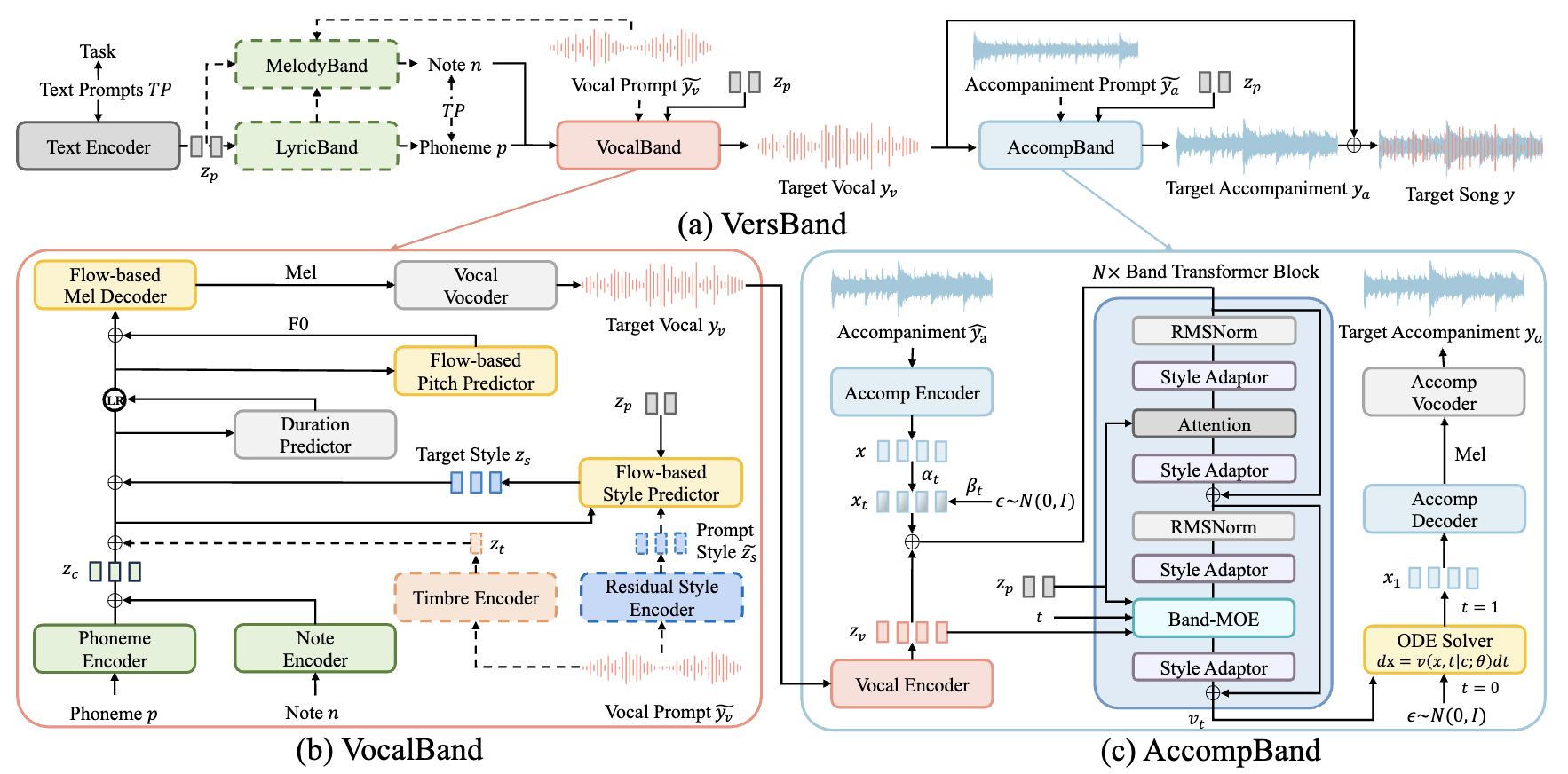
Versatile Framework for Song Generation with Prompt-based Control
Yu Zhang#, Wenxiang Guo#, Changhao Pan#, et al.

- VersBand is a multi-task song generation framework for synthesizing high-quality, aligned songs with prompt-based control.
Others
IEEE-TVCGInteractive Table Synthesis with Natural Language, Yanwei Huang, Yunfan Zhou, Ran Chen, Changhao Pan, Xinhuan Shu, Di Weng, Yingcai Wu.